Grasshopper itself is a single-threaded process. That is, even if you have a very complicated calculation going on, and you have a powerful computer with many cores, it persists in using a single core. This is very frustrating when you end up waiting a long time for calculations to complete.
However, it doesn’t have to be the case that each component is single-threaded. Nearly all components are single-threaded, but when you create your own compiled component, there’s nothing to stop you from defying convention and making some lightning-fast multi-threaded components. And, as I have just found out, it’s very easy to set up.
While the code is simple, knowing when it is okay to use multi-threaded logic is a bit more challenging. Multi-threading works best when you have a single repetitive task. Rather than multithreading the entire component, you select bits of your code that are taking a long time to calculate, and set those up for multithreading.
Say you have a foreach loop. You might be looping through a list of 100000 points in a model, checking if they are intersecting a shape. You then build a list of true/false that describes if each point is intersecting that shape. In regular single-threaded programming, your loop would go through each point one at a time, doing the intersection result and saving the result to your list.
This is a prime candidate for multithreading. The task is repetitive, and very importantly, each loop is independent, i.e. any one loop’s action does not depend on the result of any other loop.
With multi-threading, instead of running one at a time, we can divide the task up for each core on your computer. For example, if you have 2 cores, one core does half of the loops and the other does the other half.
.NET has some very useful classes/methods that really simplify setting this up. There are many of these for different tasks, but here we will focus on one in particular. Note that, as far as I know, these parallelisation tricks only work for compiled components (such as those created in Visual Studio) and won’t work in the c# script component within Grasshopper.
How to convert a ‘foreach’ loop into a parallel foreach loop
Let’s say you have the following foreach loop, which sends an output of results to Grasshopper:
var results = new List<bool>(new bool[pts.Count]);
foreach (Point3d pt in pts)
{
bool isIntersecting = CheckIntersection(pt, shape);
results.Add(isIntersecting);
}
DA.SetDataList(0, results);
This code uses a method I wrote, CheckIntersection, to see if a list of points are interacting with an input shape.
We set up a list to take our results, we cycle through our points, do a calculation on each, and then save the result. When finished, we send the result as an output back to Grasshopper. Simple enough.
The best thing to do is I show you how to parallelise this, and then explain what’s happening. Here’s the parallel version of the above code:
var results = new System.Collections.Concurrent.ConcurrentDictionary<Point3d, bool>(Environment.ProcessorCount, pts.Count);
foreach (Point3d pt in pts) results[pt] = false; //initialise dictionary
Parallel.ForEach(pt, pts=>
{
bool isIntersecting = CheckIntersection(pt, shape);
results[pt] = isIntersecting; //save your output here
}
);
DA.SetDataList(0, results.Values); //send back to GH output
Going from ‘foreach’ to ‘Parallel.ForEach’
The Parallel.ForEach method is what is doing the bulk of the work for us in parallelising our foreach loop. Rather than waiting for each loop to finish as in single threaded, the Parallel.ForEach hands out loops to each core to each of them as they become free. It is very simple – we don’t have to worry about dividing tasks between the processors, as it handles all that for us.
Aside from the slightly different notation, the information we provide is the same when we set up the loop. We are reading from collection ‘pts’, and the current item we are reading within ‘pts’ we will call ‘pt’.
The concurrent dictionary
One real problem though with multithreading the same task is that sometimes two or more processes can attempt to overwrite the same piece of data. This creates data errors, which may or may not be silent. This is why we don’t use a List for the multithreading example – List provides no protection from multiple processes attempting to write into itself.
Instead, we use the ConcurrentDictionary. The ConcurrentDictionary is a member of the Concurrent namespace, which provides a range of classes that allow us to hold and process data without having to worry about concurrent access problems. The ConcurrentDictionary works just about the same as regular Dictionaries, but for our purposes we can use it much like a list.
It is a little more complicated to set up, as you need to specify keys for each value in the dictionary, as well as the value itself. (I have used dictionaries once before here.) Rather than having a collection of items in an order that we can look up with the index (the first item is 0, the second item is 1 and so on) in a dictionary we look up items by referring to a specific item. This specific item is called the ‘key’. Here, I am using the points as the key, and then saving their associated value (the results we are trying to calculate) as a bool.
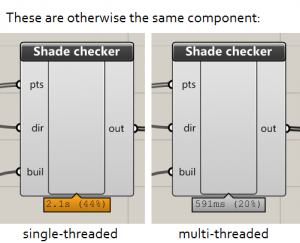
How much faster is parallel computation?
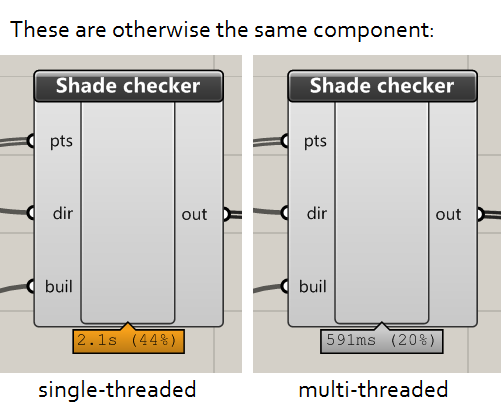
Basic maths will tell you that you will that your code should increase at a rate of how many cores you have. With my 4-core machine, I might expect a 60 second single-threaded loop to complete in about 15 seconds.
However, there are extra overheads in parallel processing. Dividing up the work, waiting for processes to finish towards the end, and working with the concurrent dictionary, all take up processor power that would otherwise be used in computing the problem itself.
In reality, you will still likely get a substantial improvement compared to single-threaded performance. With 4 cores, I am finding I am getting a performance improvement of around 2.5 to 3.5 times. So a task that would normally take 60 seconds is now taking around 20 seconds.
References
Thanks to David Greenwood for getting me started with multithreading. Front image source under CC licence.